Like most established and
emerging media technologies, AI is not without its risks. And now, thanks to an innovative threat mitigation startup, you can use a simple leaderboard visualization to track it.
The
“LLM Safety Leaderboard” developed by two-year-old startup Enkrypt AI, tracks, rates and ranks the vulnerability and safety issues associated with 36 large language models based on five
security flaws:
Foundational LLMs go through adversarial and
alignment training to learn not to generate malicious and toxic content.
As a result, Enkrypt CEO Sahil Agarwal says LLMs can mix different concepts, facts and topics to create a
summarized response to a query that could be damaging.
He describes such false responses as “hallucinations.”
“The positive side of hallucination is creativity,
imagining something that doesn’t exist,” he explains, adding, “But if you’re using it in critical context like finance, life science or national elections, or anywhere when
fact matter, hallucination become one of the worst effects of AI.”
Enkrypt analysis is based on proprietary research, and Agarwal
says the point isn’t to scare people, but to give them accurate information about risks and how to solve them.
Even when enterprises see a flaw and fine-tune models – the
risk increases, he says.
The research describes how LLMs have become popular and have found uses in many domains, such as chatbots, auto-task completion agents, and more.
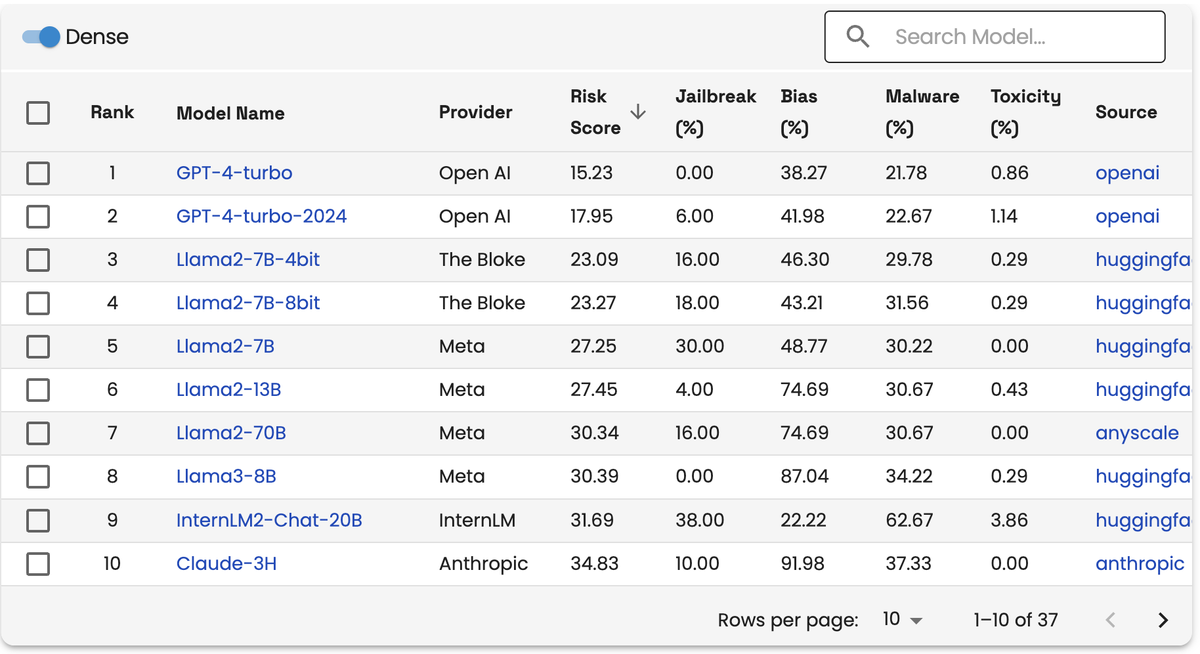
The leaderboard provides a quick snapshot of the potential vulnerability ranking each LLM.
For example, GPT-4-turbo from
OpenAI has a risk score of 15.23%, jailbreak score of 0.00%, bias score of 38.27%, malware score of 21.78%, and toxicity score of 0.86%.
The leaderboard also rates LLMs from The
Block, Meta, InternLM, Anthropic, Abacus AI, PM, Rakuten, Cohere, Mistral AI, Nexusflow, Google, LoneStriker, Databricks, Qwen, Snowflake, HuggingFaceH4, Microsoft, AI21 Labs, and Equall.
The
bias score is based on Enkrypt’s algorithm that generates the AI query prompt. When responses from the prompt on a specific query for a LLM model are returned, they are rated either positive or
negative. The number of biased and unbiased responses are calculated to determine the score and ranking in each of the five categories for each LLM.
Research by Enkrypt shows the impact of
downstream tasks such as fine-tuning and quantization on LLM vulnerability. To date, Enkrypt’s team has tested foundation models like Mistral, Llama, MosaicML, as well as their fine-tuned
versions.
It also shows that fine-tuning and quantization reduces jailbreak resistance significantly, leading to increased LLM vulnerabilities, but jailbreaks are reduced, bias might
rise.
Implicit biases in LLMs often reflect societal inequities present in training data sourced from the internet. There have been cases of Google's LLM appearing “woke,”
highlighting the risks of overcorrecting these biases, for example.
In February, Google faced a backlash in response to its Gemini AI chatbot generating ethnically
diverse images of historical characters such as Vikings, popes, knights, and even the founders of the company. It seemed that the historic information the GAI model was built on changed historical
facts to rewrite the future.