Large language models (LLMs) and vision language models (VLMs)
require massive amounts of text and images to train AI models, with data scraped from the internet or licensed from publishers. They also learn by interacting with the physical world.
A new
project developed by researchers at Google DeepMind and Imperial College London changes the learning process for AI models used in robotics, and could do the same for any AI models. It's important to
note the research does not mention online advertising or search, but the project is in its early stages of "lifelong learning."
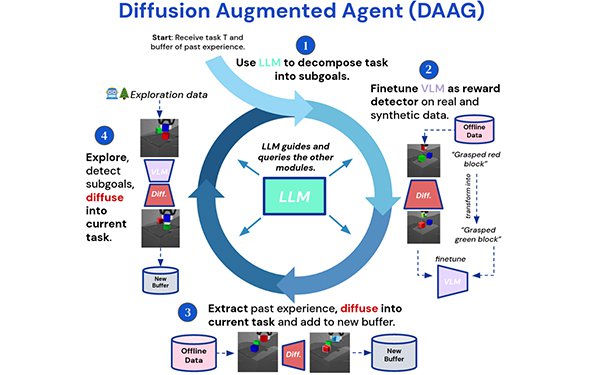
Diffusion Augmented Agents (DAAG), the team's project, is a
framework that combines LLMs, VLMs, and diffusion models to improve the learning process and transfer capabilities to AI agents.
These agents are software programs that can perform tasks
on behalf of a user, often with intelligence that mimics human-like behavior.
advertisement
advertisement
The joint project is designed to enable agents to generate synthetic data by using past
experiences.
DAAG is described as "a lifelong learning system," which means that the AI agent continuously learns and adapts to new tasks, so it initially requires less data to fine-tune
a VLM and train reinforced learning (RL) agents on new tasks, the researchers write in the report.
In simulated robotics environments that manipulate and navigate an AI model, the results show
that DAAG improves the ability to develop lifelong-learning AI agents that can improve efficiencies in time. Google has more information about these types of agents here.
An agent receives instructions for a task, observes the environment around it, and takes actions.
It has two
buffers for memory. One is a task-specific buffer that stores experiences for the current task, and the other is an offline lifelong
buffer that stores all past experiences, regardless of the task or the outcome.
DAAG uses Hindsight Experience Augmentation (HEA), a process that uses VLM and a diffusion model
to help the agent learn and retain a memory.
The VLM processes visual signals that have been buffered and compares them to the goals, adding relevant observations to the agent’s new
buffer to help guide actions. However, if the experience has been buffered and does not meet the criteria, the diffusion model steps in to generate synthetic data to help the agent complete
the desired action.
The capability to use this type of AI model in ad targeting would have many possibilities. Based on prior learning and less data from consumers to protect privacy, it would
target the ad with specific criteria to create the perfect match.