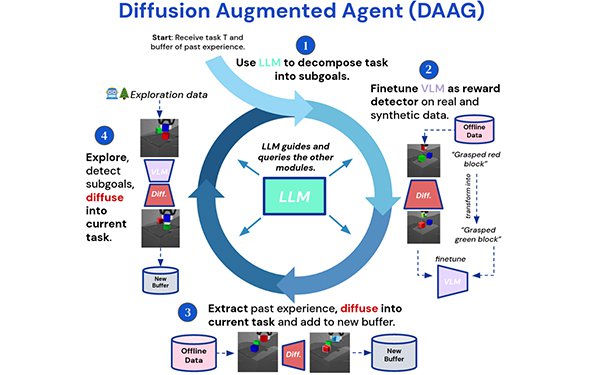
Large language models (LLMs) and vision language models (VLMs)
require massive amounts of text and images to train AI models, with data scraped from the internet or licensed from publishers. They also learn by interacting with the physical world.
A new
project developed by researchers at Google DeepMind and Imperial …