Google
has developed a method it calls audiovisual speech separation. It used machine learning to identify
specific speech sounds from audio in video.
The technology does more than just isolate the verbalized words from the background and other sources. It can separate the speech patterns of two or
more people talking.
The details posted in a Google Developers’ blog describe the technology, which also includes several videos demonstrating how it works.
The technology
can separate background and ambient noise on one audio track. Researchers believe this capability can have a range of applications, from speech enhancement and recognition in videos and voice search
to video conferencing and the ability to improve hearing aids.
advertisement
advertisement
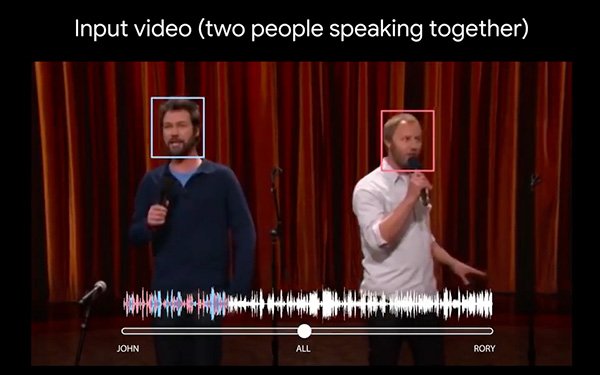
The technique combines auditory and visual signals of an input video to separate the speech. The visual signal aims to improve
the speech separation quality in cases of mixed speech -- but more importantly, it also associates the separated speech tracks with the visible speakers in the video.
Researchers explained
that when training the model they used a large collection of 100,000 high-quality videos of lectures and talks from YouTube. From the videos they extracted segments with a clean speech, which means
they removed any sounds of music and other speakers. It results in about 2,000 hours of video clips, each of one person visible to the camera and talking with no background interference.
Google provides several videos in which researchers were able to separate the speech of two people talking such as sports commentators and someone talking in a noisy cafeteria.
The
technology also can be used for automatic video captioning.