Anthropic has
detailed and made public its safety strategy to keep the company’s AI model Claude from inflicting harm.
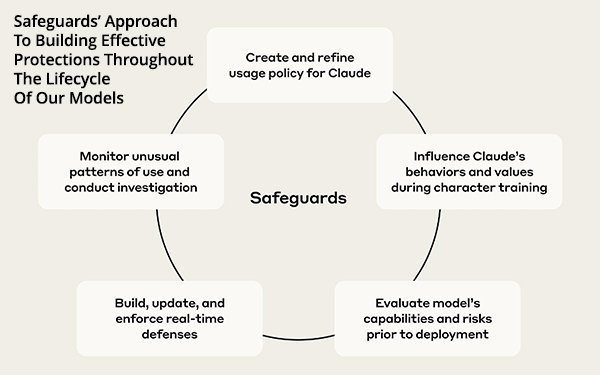
Data, analysis, and analytics are a major part of safeguards. Anthropic’s
team has a mix of policy experts with data scientists, engineers, and threat analysts to identify potential misuse,
responds to threats, and builds defenses intended to keep Claude helpful and safe.
The group tests the model for harmful outputs, enforces policies in real-time, and identifies misuses and
attacks. This approach trains, tests, and spans the entire lifecycle of models.
A video from several months ago helps explain the importance of this team by outlining how Claude thinks and
makes decisions. It apples to marketers and advertisers who buy media, write copy, and build campaigns through AI.
advertisement
advertisement
It is part of a post from May that explains how Anthropic created attribution
graphs to study the thought and reasoning process of a large language model (LLM), Claude 3.5 Haiku, the company’s “lightweight production model” released in October 2024. Engineers
took the model through a variety of contexts, using its circuit tracing methodology.
The research paper describes multistep reasoning. It outlines how the model thinks in advance of providing
a response. In one instance, Anthropic uses Claude to write a poem using a mixture of language-specific and abstract and language-independent circuits.
Language models like Claude are not
programmed. They are trained on large amounts of data. They learn their own strategies to solve problems during this process. These strategies are encoded in the billions of computations a
model performs for every word it writes.
When this test was conducted in May, the company admitted it did not completely “understand how models do most of the things they do.”
Claude writes text one word at a time, but it does plan ahead by thinking out entire concepts -- not just one, but many.
For example, with the first line of a poem -- “He saw a carrot
and had to grab it” -- Anthropic engineers found that Claude planned a second line that rhymed even before finishing the first line. Claude saw the words “carrot,” which is a
subject, and “grab it,” which is an action. Then the LLM tied that sequence of words to rabbit and wrote the rest of the line, “His hunger was like a starving rabbit.”
But engineers also saw other ways the LLM could have finished the poem with words like “habit.” Anthropic made further changes to the model, and the LLM returned the words “His
hunger was a powerful habit.”
Engineers tested the model for hidden secret goals by exploiting bugs in its training process.
While the model avoids revealing its goal when asked,
Anthropic’s method identifies mechanisms in pursuing the goal. Interestingly, these mechanisms are embedded within the model’s representation of its “Assistant” persona.
Certain steps allowed the model to distinguish between familiar and unfamiliar entities, which determine whether it elects to answer a factual question or profess ignorance. In the paper, Anthropic
described how "'misfires' of this circuit can cause hallucinations."
There was evidence that the model constructs “harmful requests” during fine-tuning of the model, aggregated
from features representing specific harmful requests learned during pre-training, the company said.
At the time of this paper, the model could be tricked into starting to give
dangerous instructions "'without realizing it,' after which it continues to do so due to pressure to adhere to syntactic and grammatical rules.”
Then there is something Anthropic calls
“faithfulness of chain-of-thought reasoning,” where engineers could distinguish between cases where the model genuinely performs the steps it says it is performing -- "cases where it
makes up its reasoning without regard for truth, and cases where it works backwards from a human-provided clue so that its 'reasoning' will end up at the human-suggested answer."
There are many instances where models have been the topic of deception or blackmail. Now the question becomes which safeguards are needed to maintain brand authenticity and control, mitigate risk,
prevent financial loss and fraud, and navigate legal and ethical challenges.