Twelve Labs, a generative artificial intelligence
(GAI) startup specializing in multimodal AI to understand video content, worked with Amazon Web Services (AWS) to develop technology that makes searching videos as easy as searching
text.
Jae Lee, co-founder and CEO of Twelve Labs, estimates that nearly 80% of the
world’s data is in video, yet most of it is unsearchable.
The technology analyzes multiple data formats -- video, audio, text -- simultaneously, and provides searchable content in more
than 100 languages.
Searches include actions, objects, and background sounds. The technology can search through videos, classify scenes, summarize, and split video clips into
chapters.
The unique features revolve around technology that content creators can access exact moments or events within a show or game using natural-language searches.
advertisement
advertisement
For example,
sports leagues can use the technology to streamline and catalog vast libraries of game footage, making it easier to search for and retrieve specific frames for live broadcasts.
Media and
entertainment companies can use the technology to create highlight reels from TV programs customized to each viewer’s interests, such as compiling all action sequences in a thriller series
featuring a favorite actor.
The two companies announced the three-year collaboration agreement and the technology today at the AWS re:Invent event in Las Vegas. Developers can now find
specific video footage of athletes’ performances with conversational queries or movie scenes from archives.
The startup uses AWS technology to train its multimodal foundation
models. It can train the models up to 10% faster while reducing training costs by more than 15%, according to Twelve Labs.
Twelve Labs' Marengo and Pegasus foundation
models provide text summaries and audio translations. They are available on the AWS Marketplace to create applications for semantic video search and text generation, serving media, entertainment,
gaming, sports, and additional industries reliant on large volumes of video.
The company used Amazon SageMaker HyperPod to train its foundation models, which are
capable of comprehending different data formats including videos, images, speech and text all at once.
This allows a deeper dive into the models to gain insights focused on just one data type.
The training workload is split across multiple AWS compute instances working in a parallel fashion, which means Twelve Labs can train their foundation models for weeks or even months without
interruption.
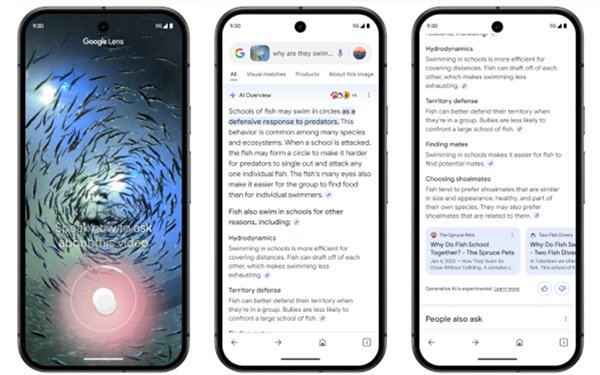
There is a lot going on in the world of video. Google reportedly is testing a video format for YouTube that provide what Glenn Gabe, SEO c
onsultant at G-Squared Interactive,
called "easy-to-digest summary of YouTube videos based on their queries." He wrote about the summaries in an X post. The pilot recently rolled out to some searchers.
A YouTube
creator reached out to Gabe with information around this "new, highly visual video search carousel: When people search queries relevant to your videos, a carousel may appear in Google Search featuring
content from you and other YouTube creators."
The feature provides users with a way to expand featured content in the carousel and view a text and image summary of the video. Summaries are
created using AI, and will feature the most relevant parts of the video for the given search query.
The persona who reached out to him said the feature also encourages people to engage with
content through an expanded summary that prompts people to watch the video on YouTube or explore your channel, Gabe says.