Large language models (LLMs) and artificial intelligence (AI)
crawlers leave a signature through a short bit of text that tells the server what is making the request.
Tyler Einberger, chief operating officer at Momentic, a boutique digital
growth and SEO agency, updated a list of AI user-agents in April that offers tips on how to identify what bots index on a website, as well as robots.txt and auditing tips.
“I
monitor those strings so I can welcome the bots that help me to build my audience and politely ask the ones that don't to leave,” Einberger jokingly wrote in a blog post.
It can
spot GPTBot, ClaudeBot, PerplexityBot, or any of the newer strings in server access logs an AI model indexes, scrapes, or quotes a page, he explains. Keeping these rules up to data can
help optimize content and prevent bots from indexing content from your site to serve in chatbots.
advertisement
advertisement
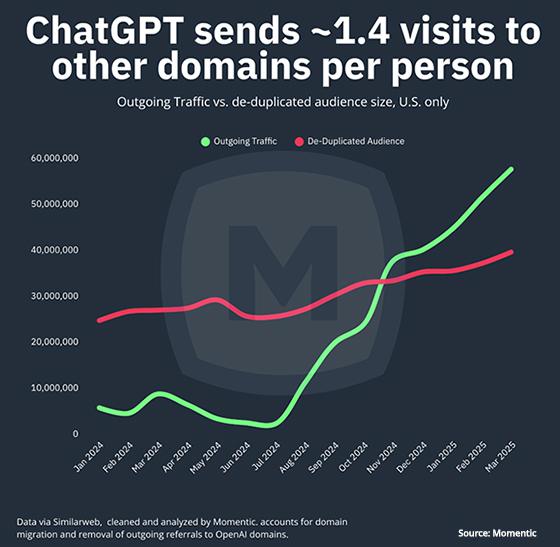
“Momentic research shows significant growth in referrals to websites from
ChatGPT,” he wrote, pointing to the graph that ChatGPT sends 1.4 visits to other domains per person. “This is over
double the rate at which Google Search sent users to non-Google properties in March 2025.”
Aimclear founder Marty Weintraub explains in a LinkedIn blog post the importance of the shift
in referral traffic sources, an increase attributable to AI-driven bots.
The company’s server log analysis has noticed user-agent strings “revealing visits from a new cohort of
crawlers associated with large language model (LLM) based applications,” Weintraub wrote in a blog post on LinkedIn.
“These aren't your traditional search engine spiders
exclusively focused on indexation,” he wrote. “We're talking about agents representing services like Google's own AI features, Anthropic's Claude, Microsoft's Copilot integrated with Bing,
and Perplexity AI, among others.”
The bots actively grab content, driven by user queries in their respective AI interfaces, which results in a referral back to the uniform resource
identifier (URI), a string of characters that identifies a resource like a web page or file. It appears that most larger search engine optimization companies belonging to holding companies do not know
how to approach this change.
Weintraub said that it required “granular analysis of your access logs. By filtering and aggregating requests based on identifying User-Agent patterns, you
can establish a baseline metric for AI bot visit frequency and volume.”
While the data is required to understand the shift, controlling how these agents interact with a website is where
the robots.txt protocol becomes important to prevent indexation, managing resources, and guiding specific user agents to appropriate sections of a site.
Weintraub suggests implementation
of well-defined Disallow and Allow directives, potentially even leveraging user-agent specific rules that allow the expert to curate the crawl behavior of the AI bots.
This ensures that
helpful agents -- those that contribute to content visibility and referral traffic -- can operate efficiently, while simultaneously mitigating potential issues with overly aggressive or unwanted
scraping that could strain server resources or expose sensitive data.
The rise of AI search bots means a more sophisticated approach to log analysis and crawler management is required.
It is a technical challenge to understand the nuances of how these new agents identify themselves, he wrote.